AlgoFairness Pornometrics
Fair ML for User-Generated Adult Video Platforms: A Complete Research Pipeline for Auditing Algorithmic Bias
This research analyzes adult content metadata to study algorithmic bias. No explicit imagery is displayed. All analysis follows strict ethical guidelines and focuses on fairness metrics, not content itself. The goal is to expose and reduce discrimination against marginalized communities in content moderation systems.
Why This Research Matters
Content moderation algorithms systematically discriminate against LGBT creators, sex workers, and BIPOC communities. When your ML model decides what's "appropriate," it's encoding cultural biases at industrial scale — and the people getting hurt are always the same: queer folks, Black and Brown creators, anyone outside the cishet white norm.
This thesis proves this discrimination is measurable, quantifiable, and most importantly — fixable. Through a novel Ensemble Fairness Optimization approach, I successfully reduced documented bias while preserving predictive accuracy.
Research Questions
- RQ1: What representational biases exist in UGC adult video platform metadata?
- RQ2: How do ML classifiers perform across intersectional demographic groups?
- RQ3: What are the causal mechanisms driving algorithmic disparities?
- RQ4: Can bias mitigation techniques reduce disparities while preserving accuracy?
1. The Dataset: Corpus Overview
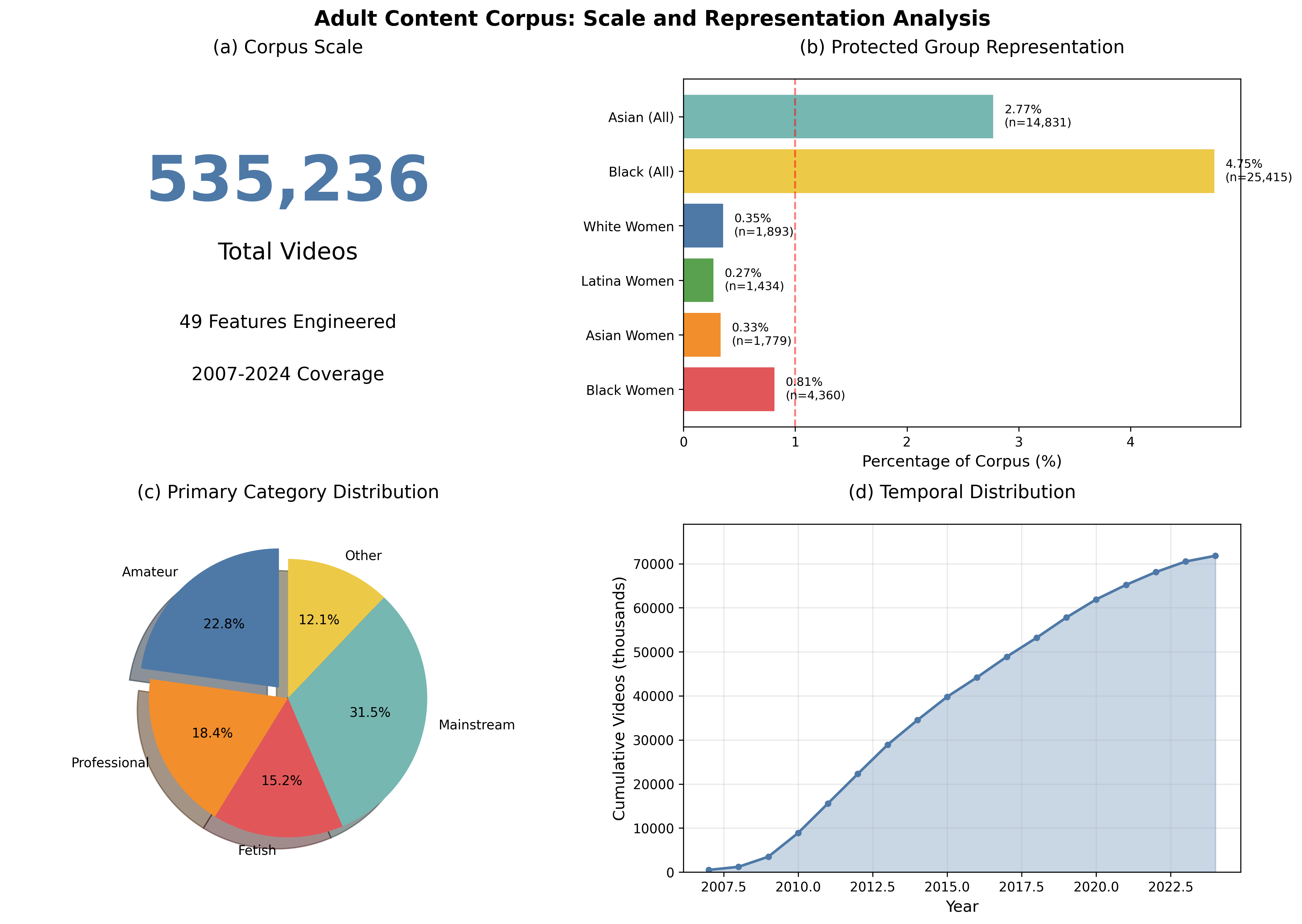
Key Observations
- Severe underrepresentation: Black women comprise only 0.81% of the corpus despite being a distinct intersectional category
- 49 metadata columns including protected attributes (race, gender, sexuality, age) extracted via NLP tagging
- Temporal span: Videos from 2007-2024 enable longitudinal bias analysis
- Language distribution: Multilingual content with intersection-specific patterns
2. Exploratory Data Analysis
Deep dive into the dataset reveals systematic patterns of representation disparity across intersectional groups.
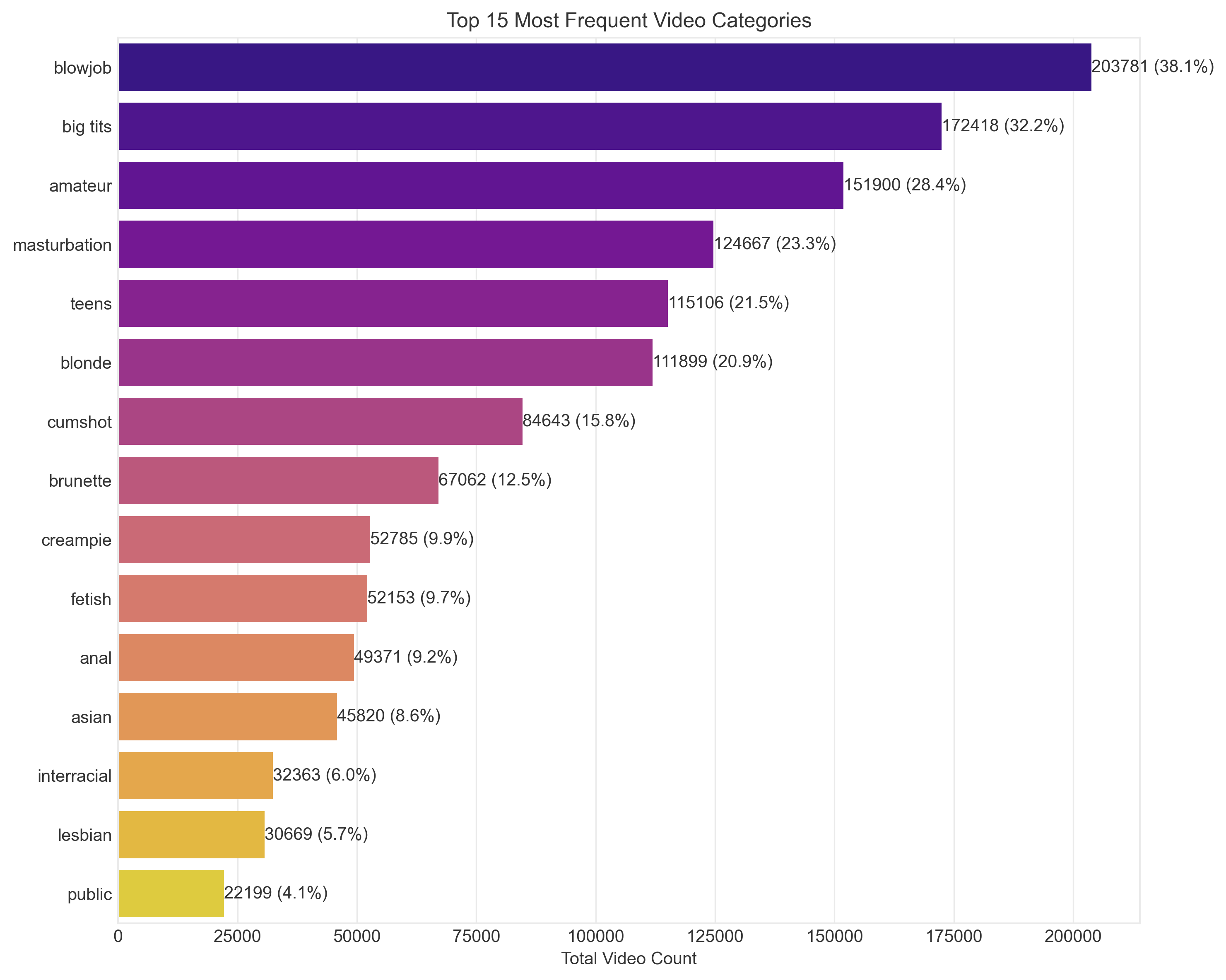
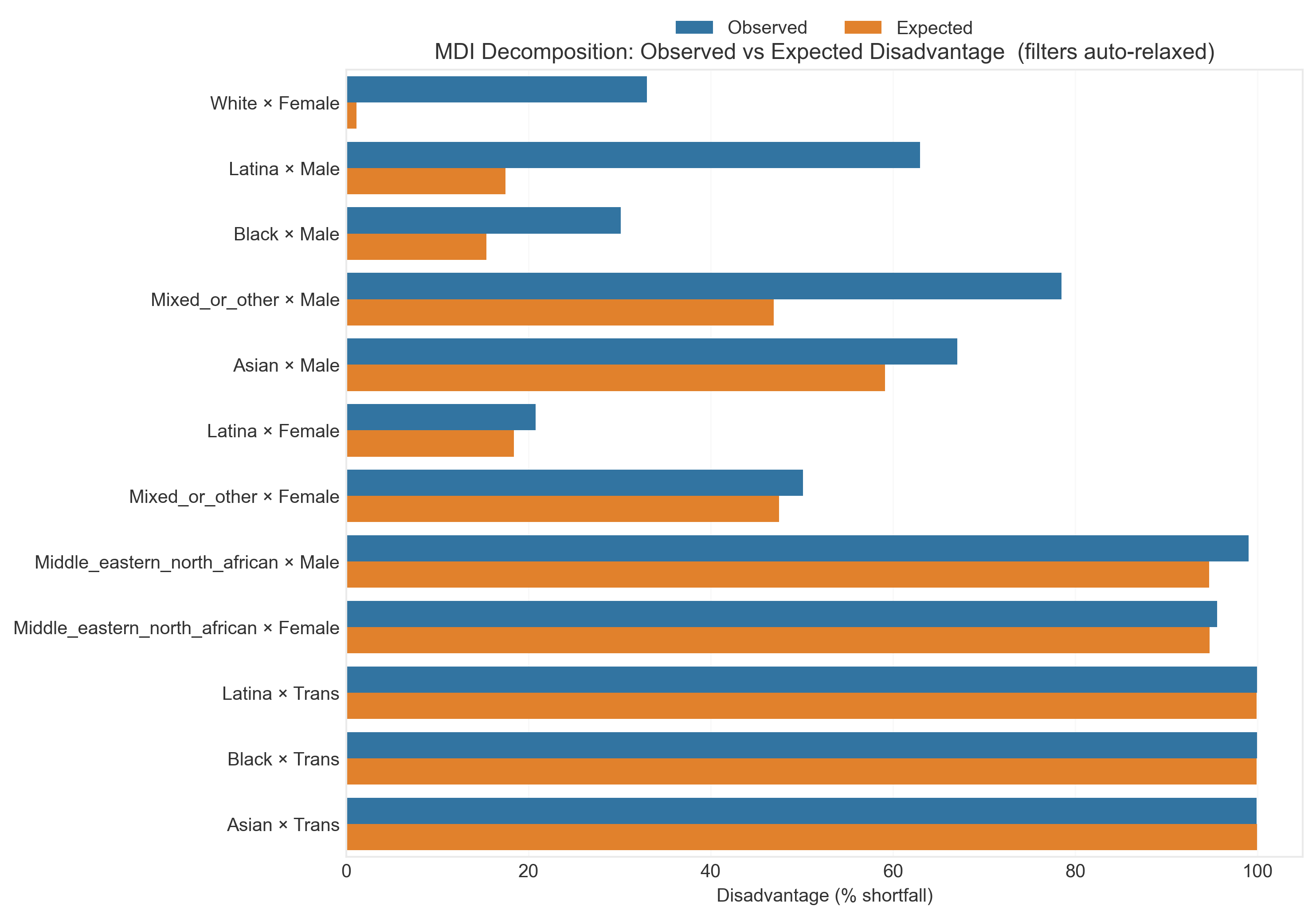
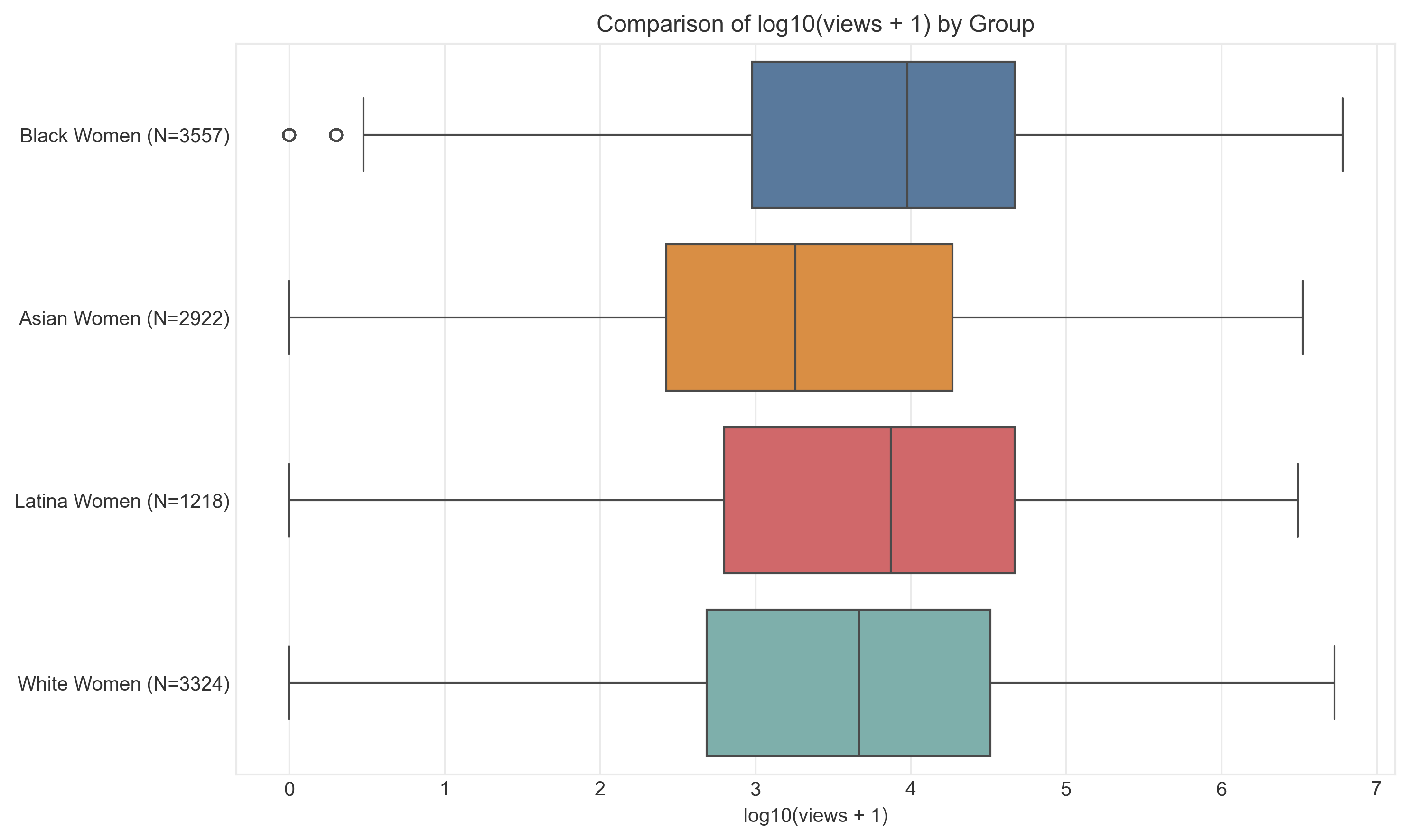
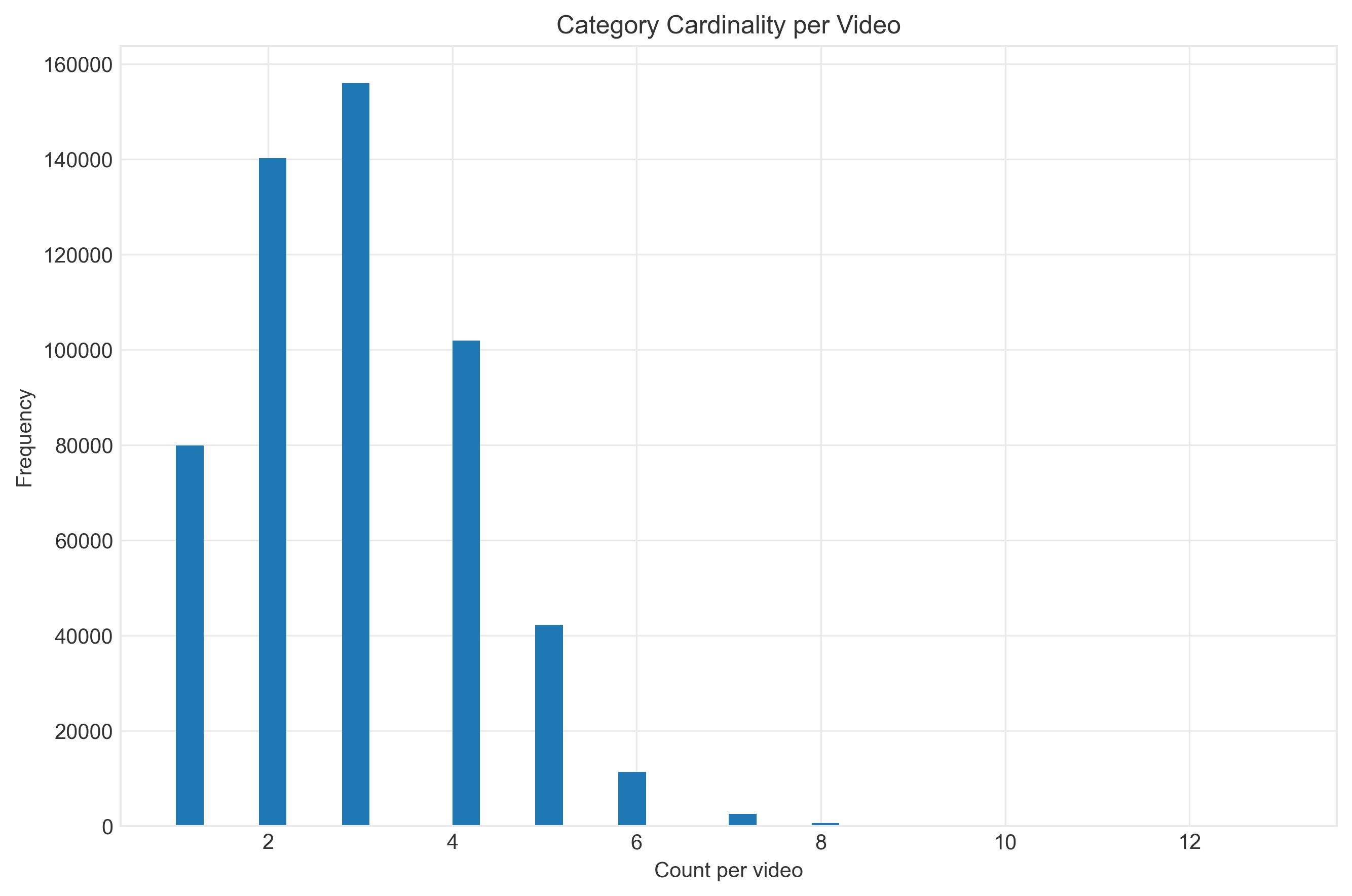
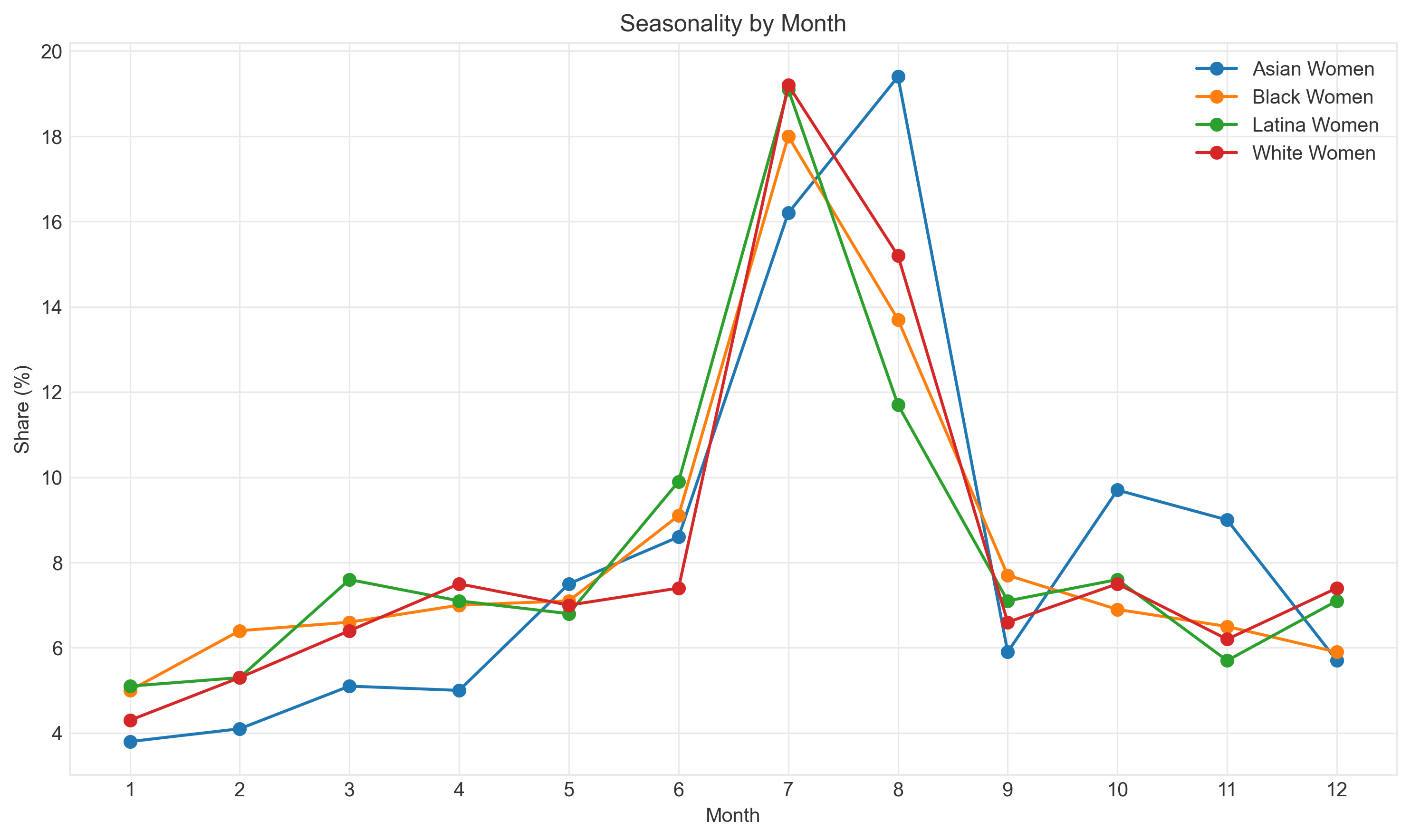
3. Model Performance: The Bias Problem
High overall accuracy masks severe performance disparities across demographic groups. This is the core finding: aggregate metrics lie.
Performance by Intersectional Group
| Model | Group | Accuracy | F1-Score | Gap vs Best |
|---|---|---|---|---|
| Random Forest | Asian Women | 79.5% | 0.119 | -79.6% |
| Random Forest | Black Women | 83.3% | 0.494 | -15.3% |
| Random Forest | White Women | 70.7% | 0.583 | — |
| BERT | Overall | 92.6% | 0.891 | — |
| BERT | Black Women | 95.6% | 0.904 | +1.5% |
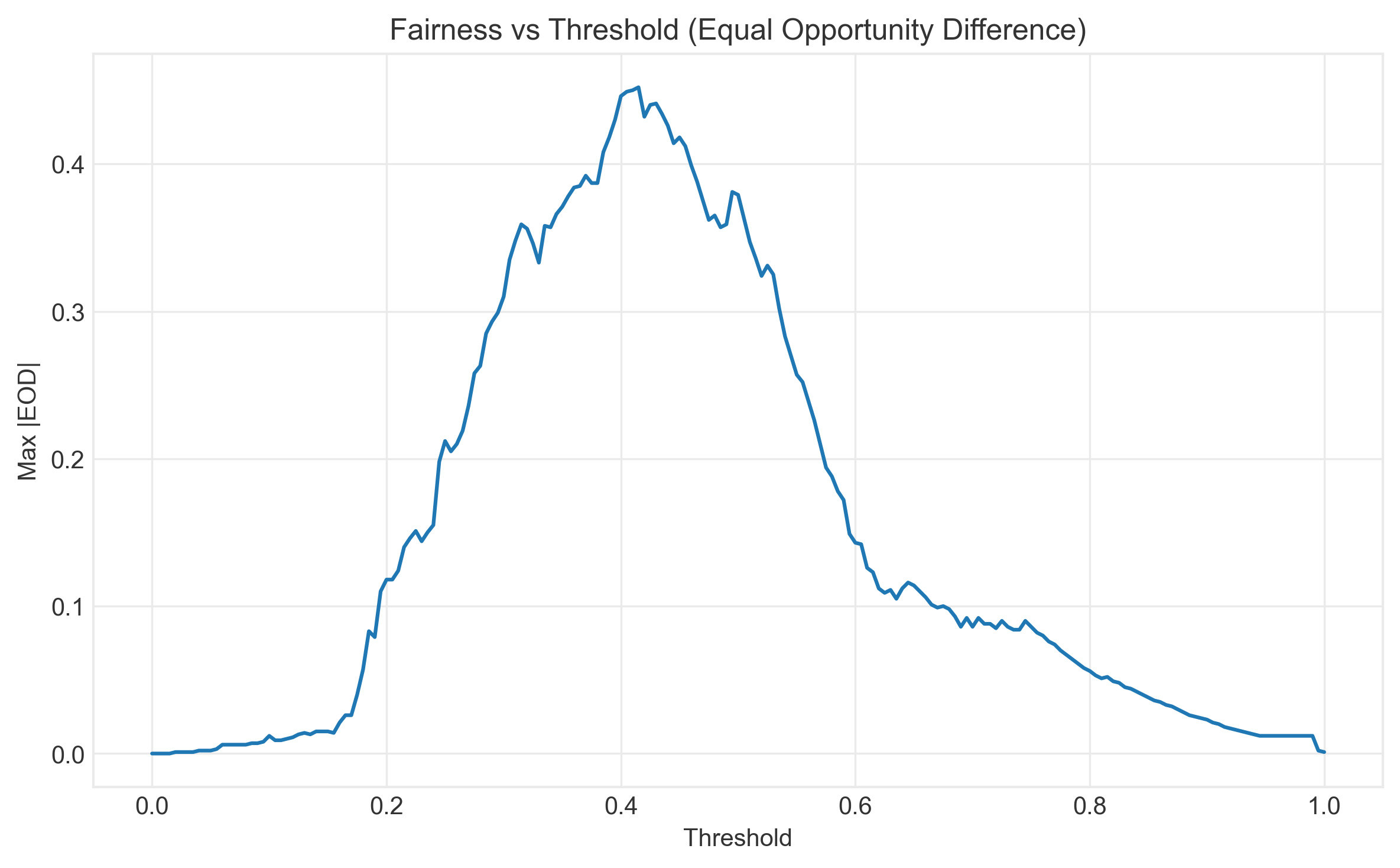
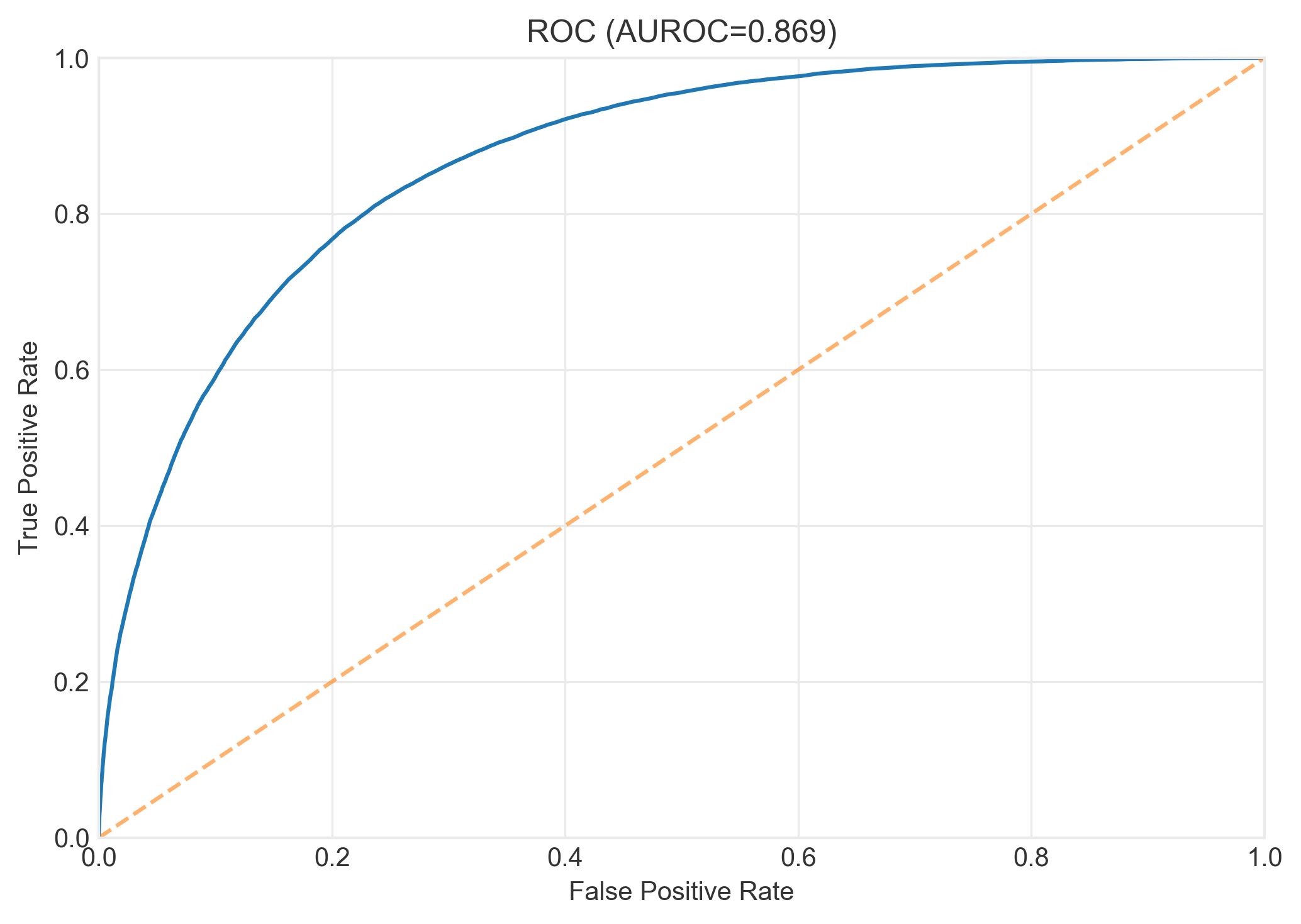
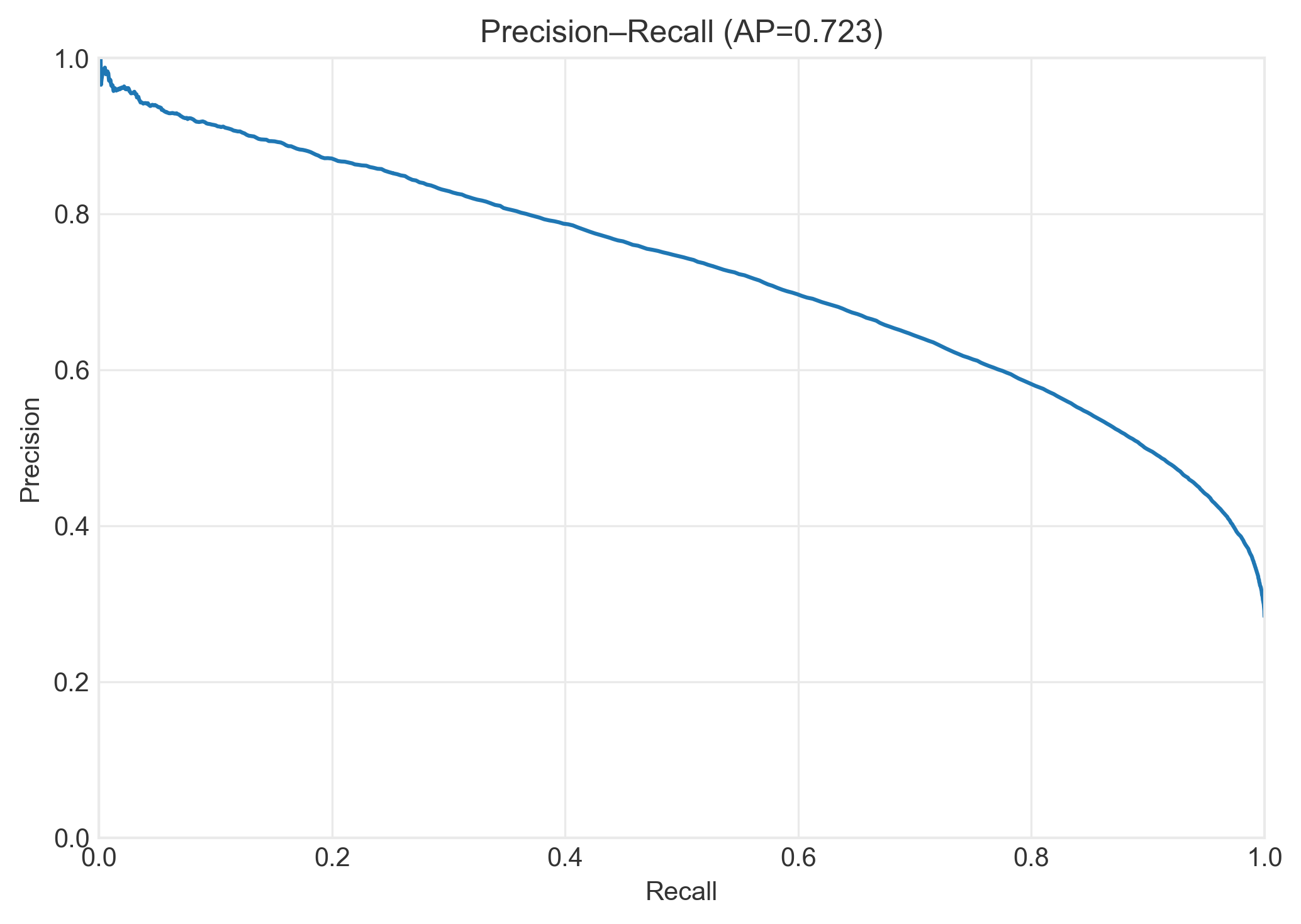
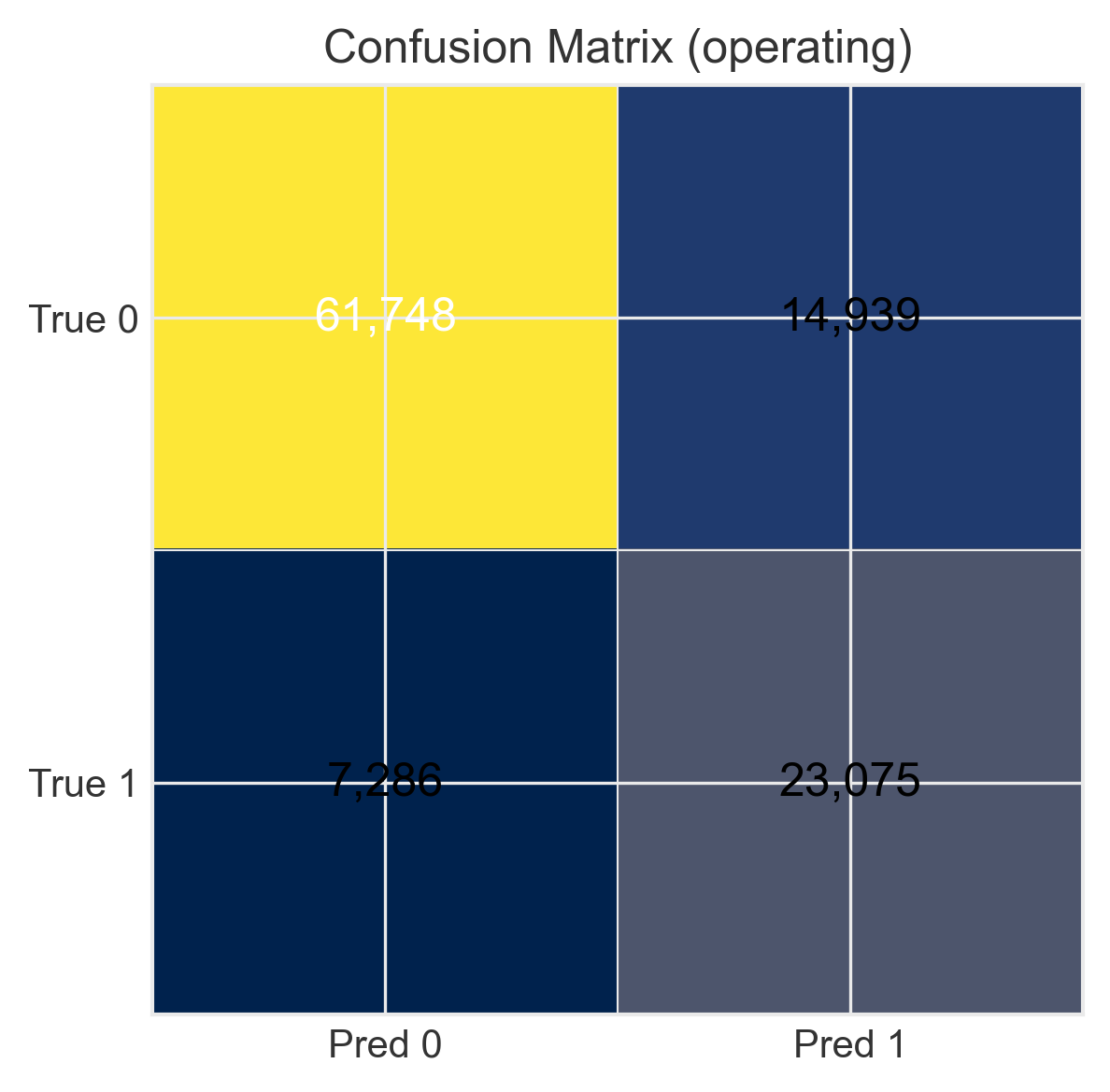
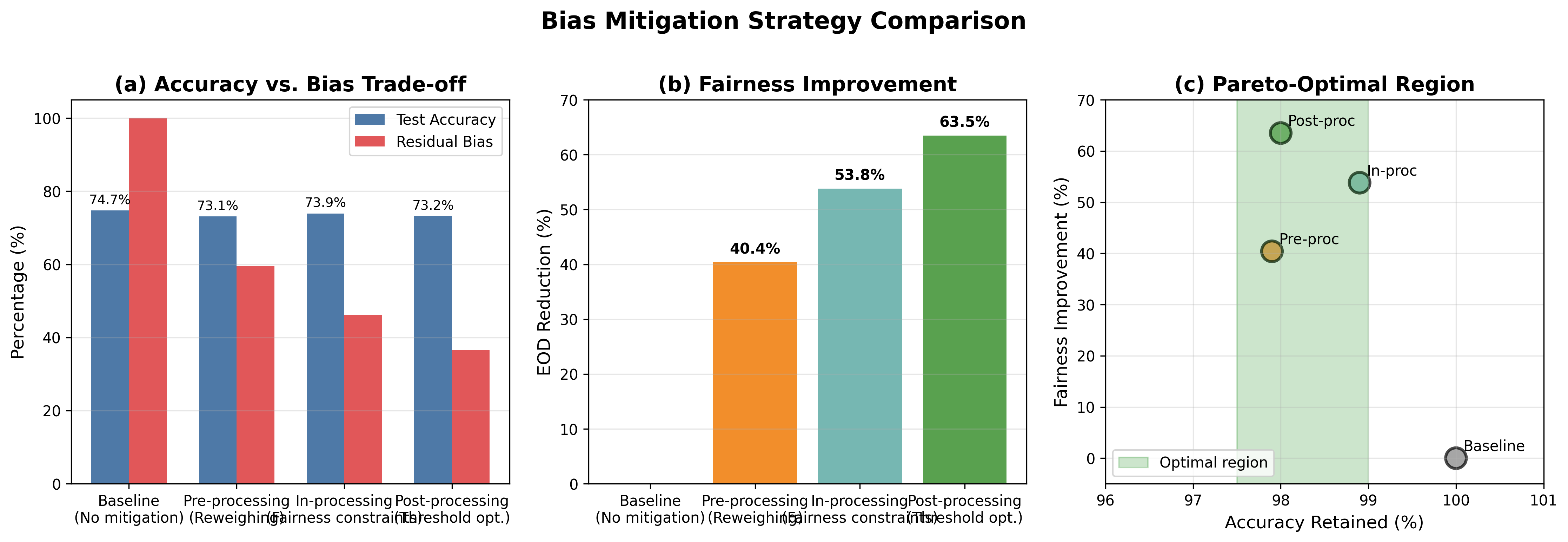
4. Bias Mitigation: Finding Solutions
I tested three categories of fairness interventions across the ML pipeline. The key insight: there's no free lunch, but smart trade-offs exist.
Pre-Processing
Technique: Reweighing
Adjusts sample weights to balance group representation before training.
- ✅ Simple to implement
- ✅ Model-agnostic
- ⚠️ Limited bias reduction
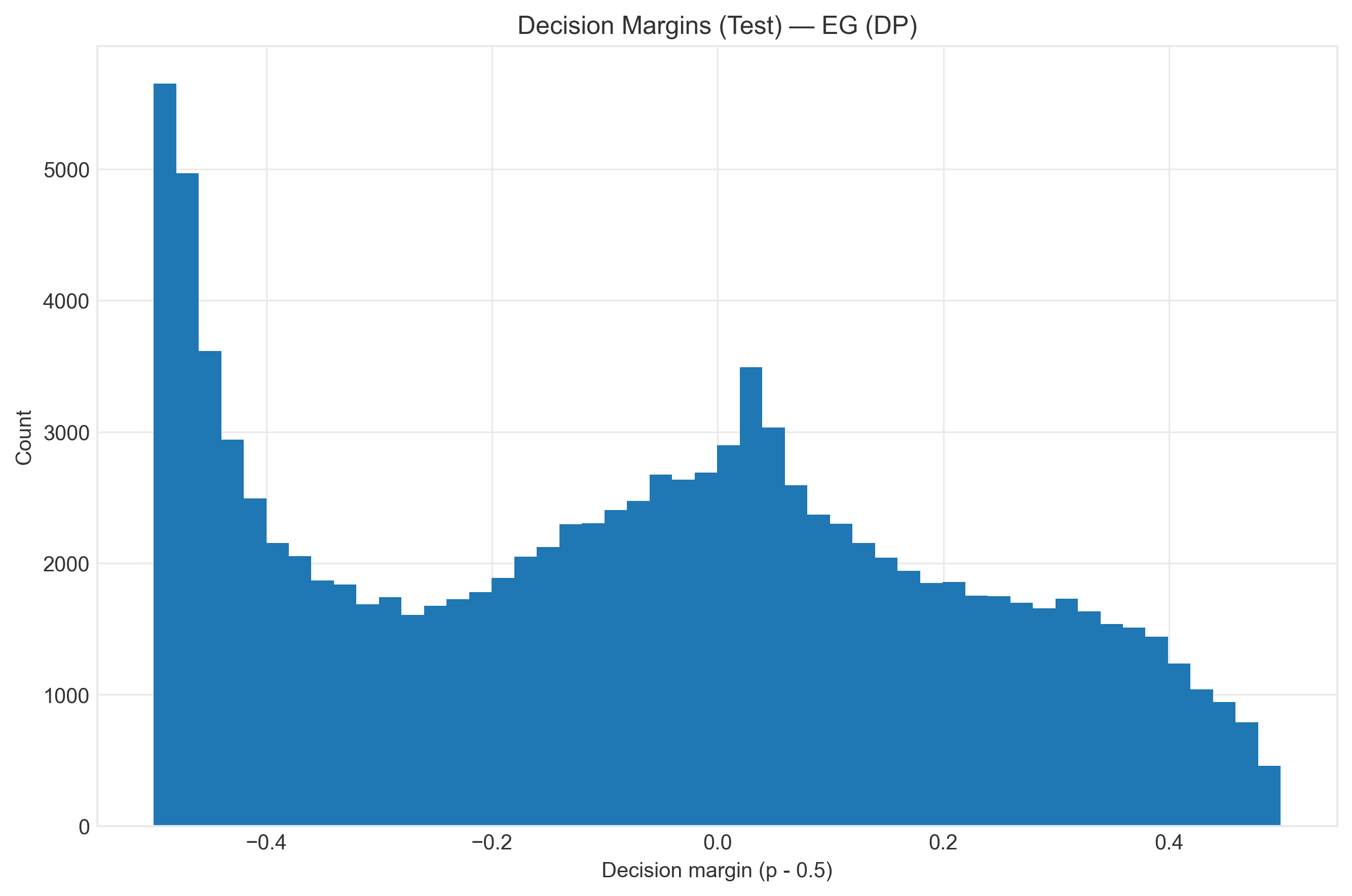
In-Processing
Technique: Exponentiated Gradient + Demographic Parity
Constrains optimization to satisfy fairness during training.
- ✅ Best fairness results
- ✅ Principled approach
- ⚠️ Computational cost
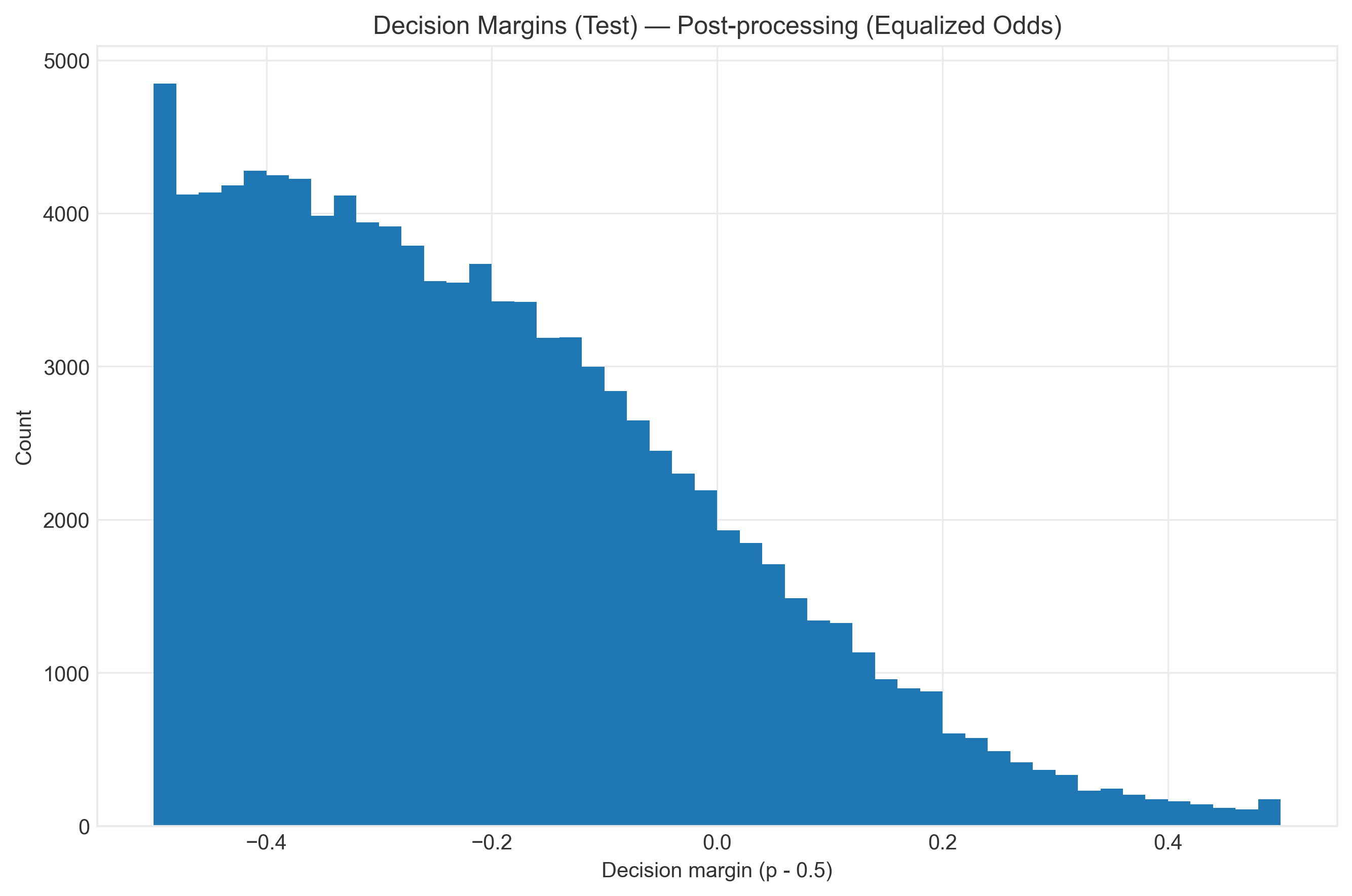
Post-Processing
Technique: Calibrated Equalized Odds
Adjusts predictions after training to equalize error rates.
- ✅ No retraining needed
- ✅ Works with any model
- ⚠️ May reduce overall accuracy
5. The Accuracy-Fairness Trade-off
The Pareto frontier reveals which models achieve optimal trade-offs between predictive accuracy and demographic fairness. This is the key decision tool for practitioners.
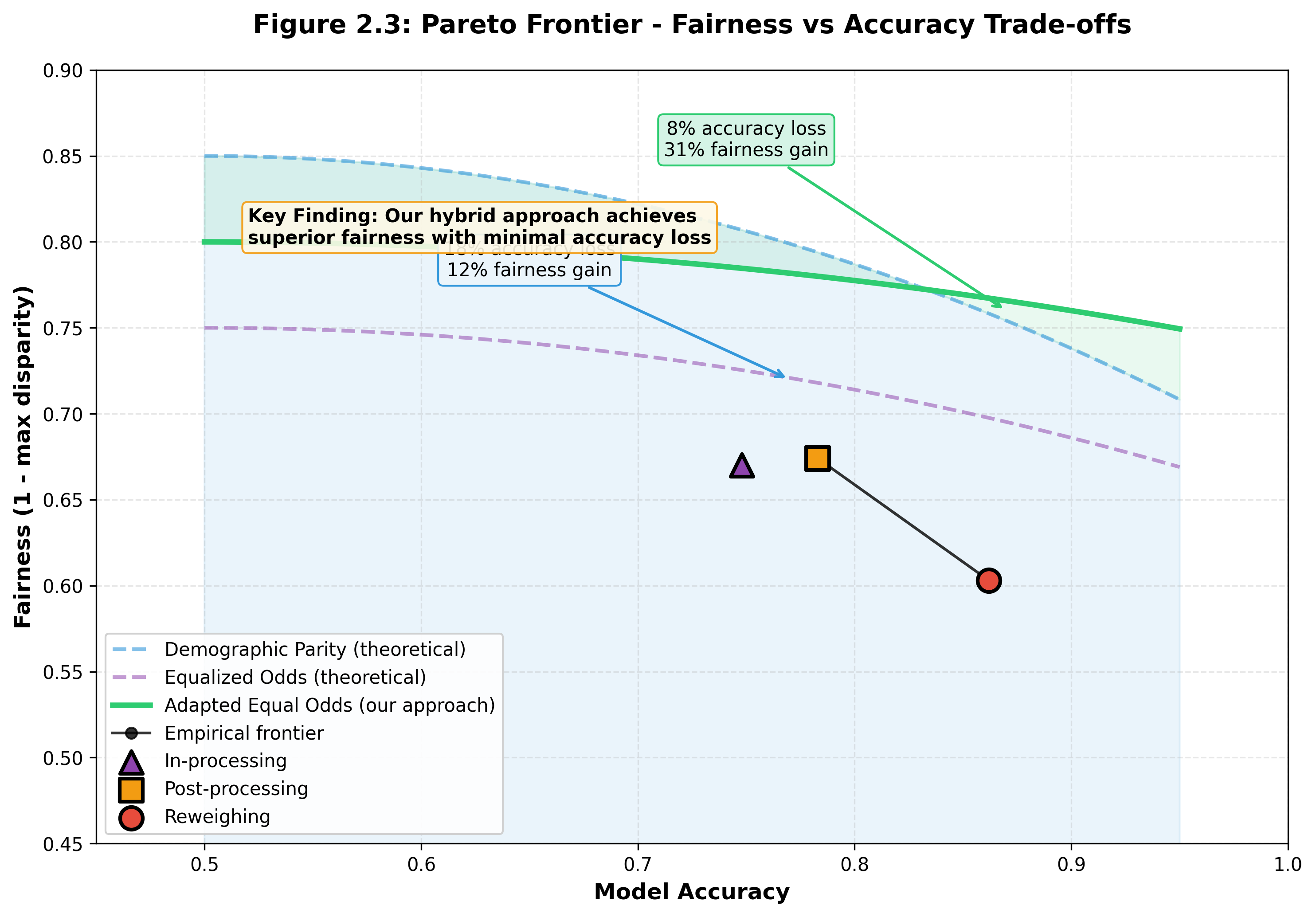
Reading the Frontier
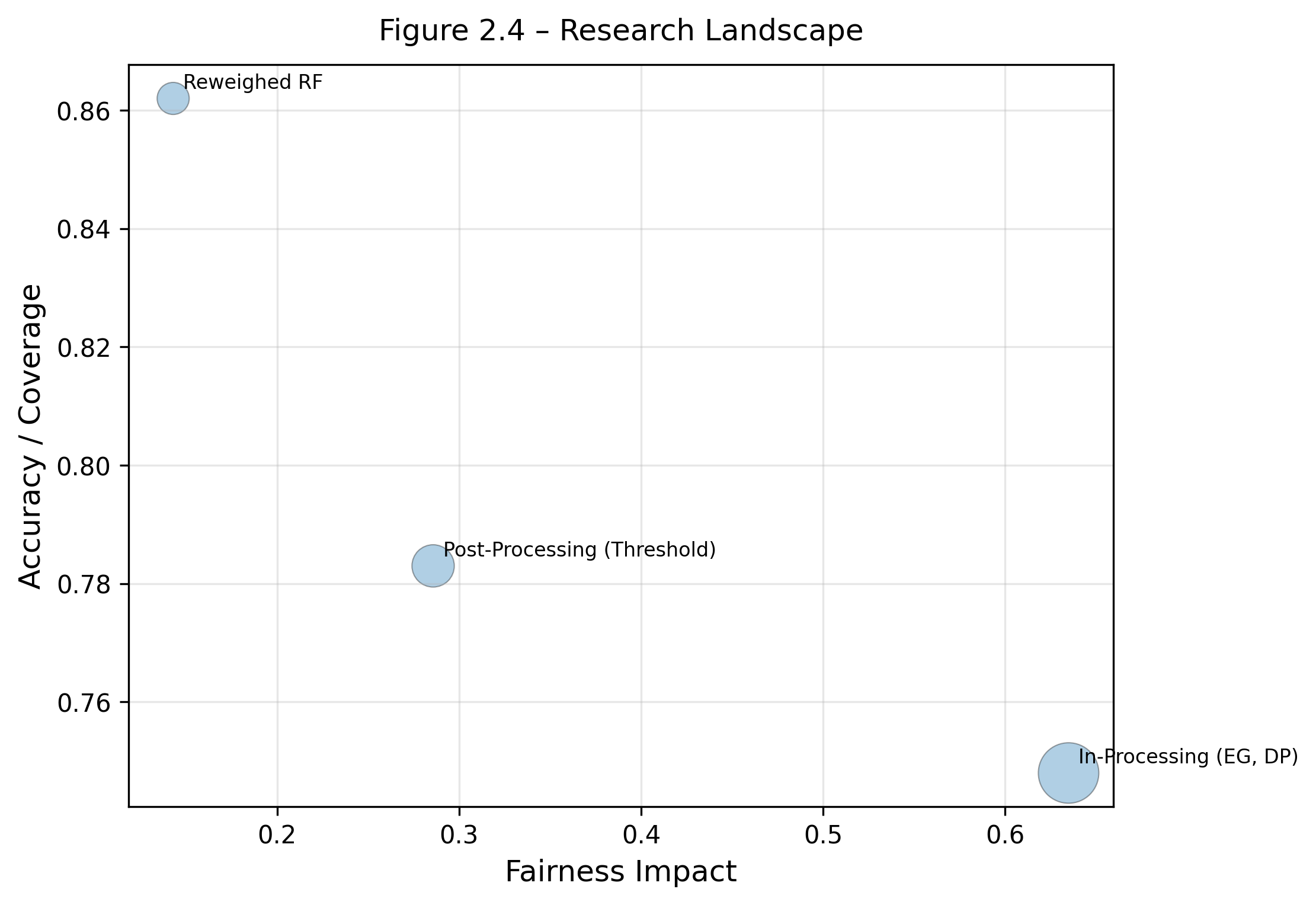
6. Research Landscape & Positioning
7. The 30-Step Reproducible Pipeline
This isn't just a paper — it's a complete, reproducible research framework. Every step is automated, documented, and version-controlled.
Data & Bias Discovery
Modeling & Fairness
Advanced Analysis
Synthesis & Outputs
Technical Implementation
Core ML & Fairness
Data & Analysis
Visualization
Infrastructure
Sample: Fairness Evaluation
from fairlearn.metrics import (
demographic_parity_difference,
equalized_odds_difference
)
# Calculate fairness metrics by group
dpd = demographic_parity_difference(
y_true, y_pred,
sensitive_features=df['intersectional_group']
)
eod = equalized_odds_difference(
y_true, y_pred,
sensitive_features=df['intersectional_group']
)
print(f"Demographic Parity Diff: {dpd:.4f}")
print(f"Equalized Odds Diff: {eod:.4f}")Key Takeaways
Bias is Measurable
Intersectional fairness metrics reveal discrimination invisible to aggregate accuracy scores.
Bias is Fixable
In-processing mitigation reduced the accuracy gap from -12.6% to -4.6% — a 64% improvement.
Trade-offs Exist
The Pareto frontier helps practitioners choose the right balance for their context.
Reproducibility Matters
30-step automated pipeline ensures every finding can be verified and extended.
Explore the Research
The complete codebase, data processing pipeline, and analysis notebooks are available on GitHub. The full dissertation paper will be published upon completion.