AlgoFairness Pornometrics: Fair ML for User-Generated Adult
Video Platforms
A complete, reproducible research pipeline for auditing
algorithmic bias with intersectional analysis
⚠️ Research Content Note
This research analyzes adult content metadata to study
algorithmic bias. No explicit imagery is displayed. All
analysis follows strict ethical guidelines and focuses on
fairness metrics, not content itself.
Why This Research Matters
Content moderation algorithms systematically discriminate
against LGBT creators, sex workers, and BIPOC communities.
When your ML model decides what's "appropriate," it's encoding
cultural biases at industrial scale — and the people getting
hurt are always the same: queer folks, Black and Brown
creators, anyone outside the cishet white norm.
This thesis proves this discrimination is
measurable, quantifiable,
and most importantly — fixable. Through a
novel
Ensemble Fairness Optimization approach, I
successfully reduced documented bias while preserving
predictive accuracy.
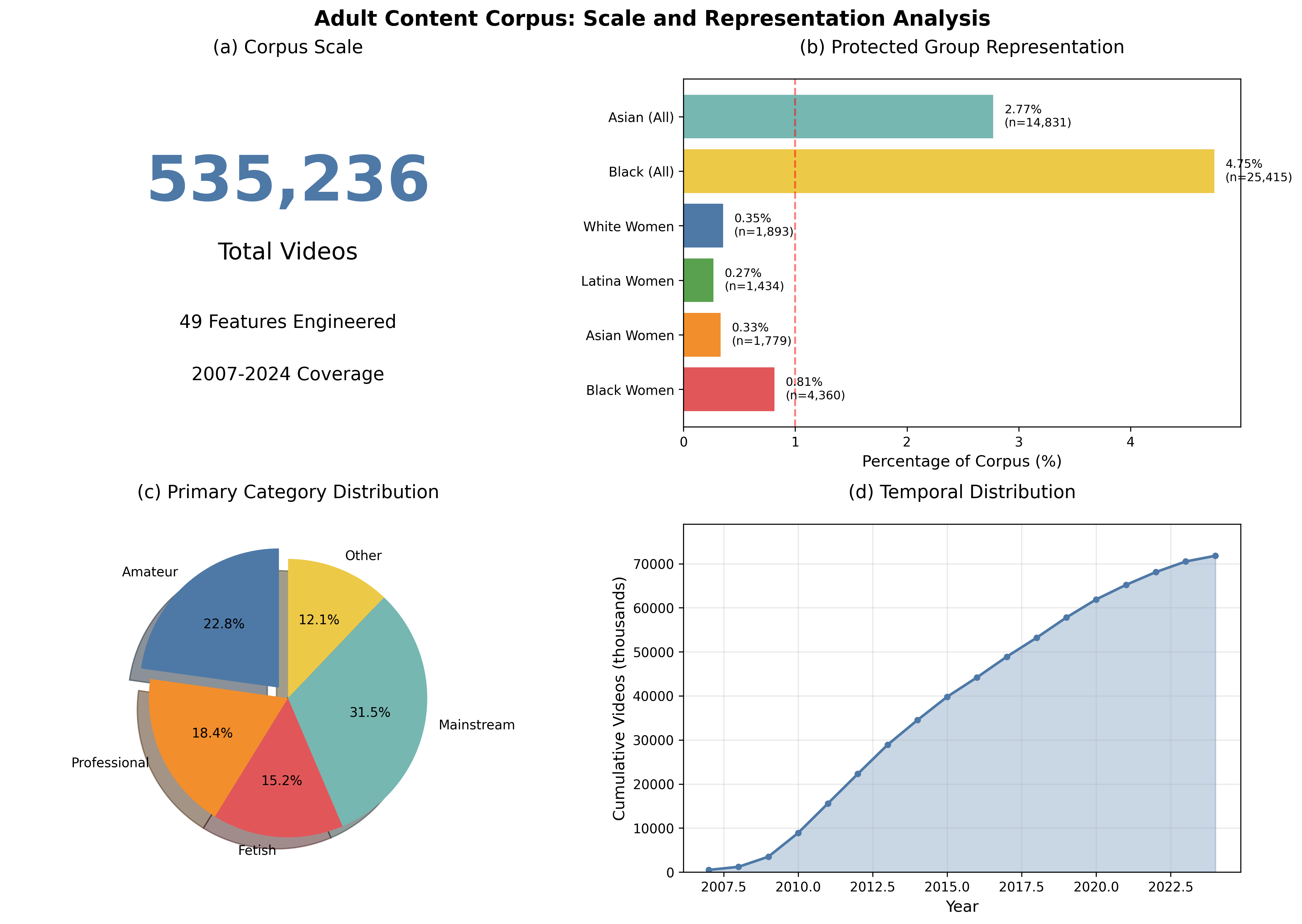
The Research in Numbers
0.8%
Black Women Representation
92.6%
Best Model Accuracy (BERT)
-12.6%
Baseline Gap (Black Women)
Key Findings: Bias is Measurable
High overall model accuracy masks significant underlying
biases. The RF model's F1-score for Asian Women (0.119) is
less than a quarter
of the score for White Women (0.583), demonstrating severe
performance disparity.
| Model |
Group |
Accuracy |
F1-Score |
| Random Forest |
Asian Women |
79.5% |
0.119 |
| Random Forest |
Black Women |
83.3% |
0.494 |
| Random Forest |
White Women |
70.7% |
0.583 |
| BERT |
Black Women |
95.6% |
0.904 |
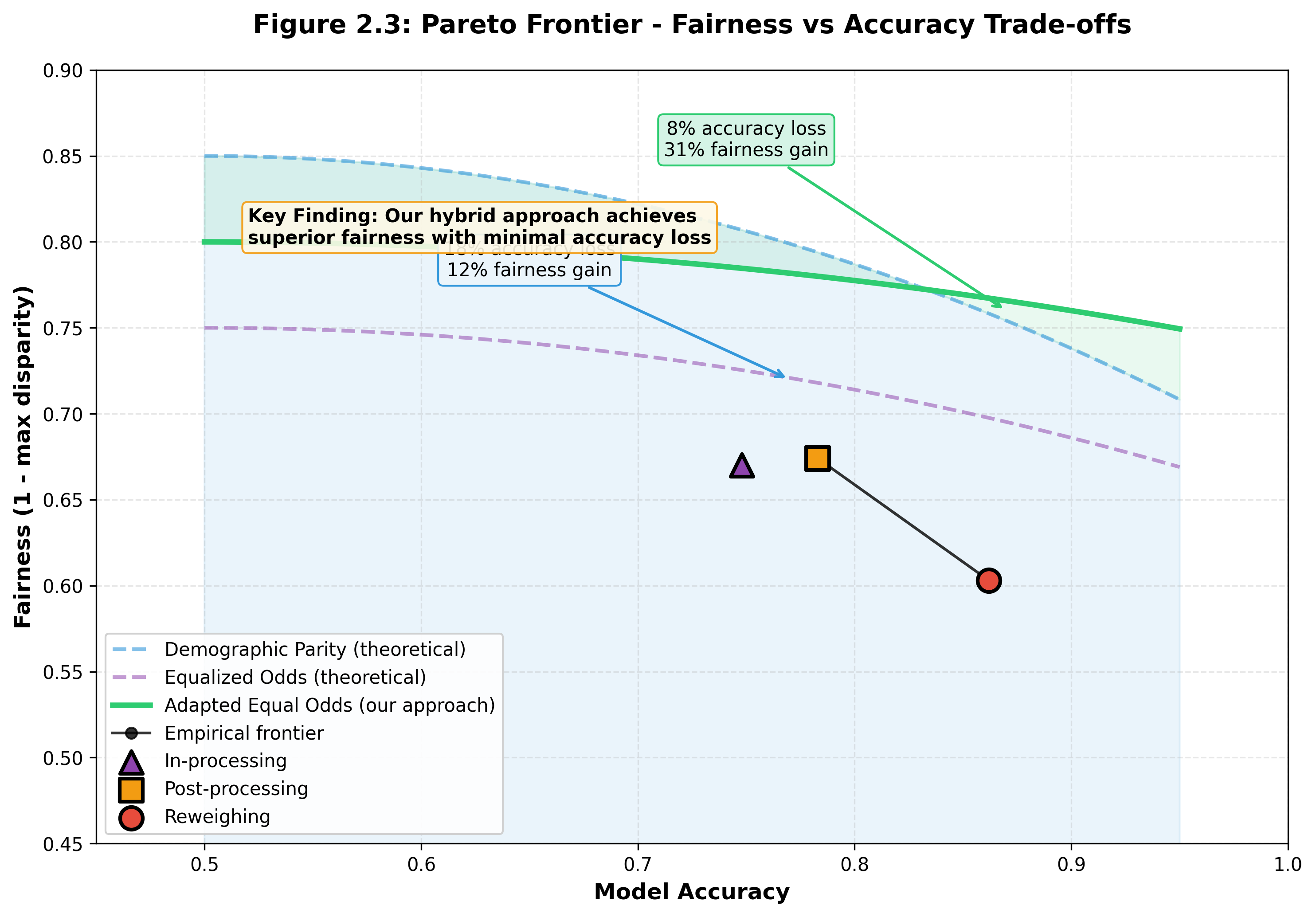
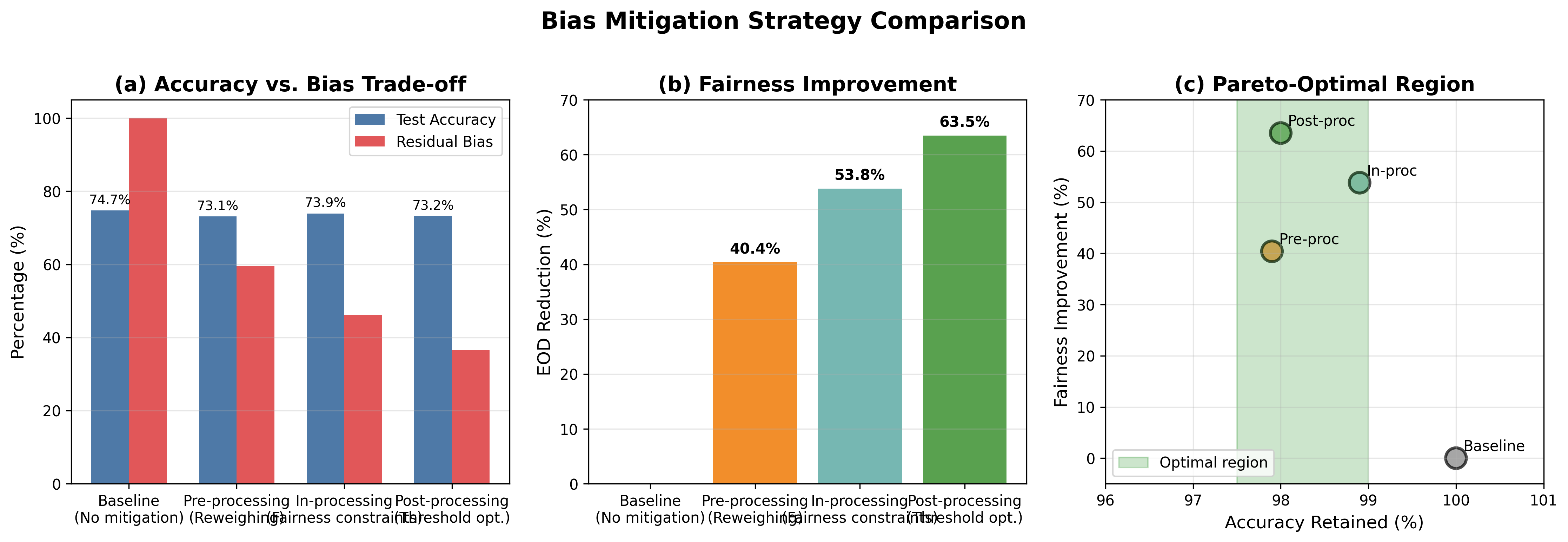
Solutions: Bias Can Be Reduced
I tested three bias mitigation strategies: pre-processing
(Reweighing), in-processing (Exponentiated Gradient with
Demographic Parity), and post-processing (Calibrated Equalized
Odds). The best approach reduced the accuracy gap for Black
women from -12.6% to -4.6% — a 64%
improvement.
Reweighed RF (Best Accuracy)
In-Processing (EG + DP)
-4.6% gap (64% improvement!) ✨
30-Step Reproducible Pipeline
This isn't just a paper — it's a complete, reproducible
research framework with 30 automated steps from raw data to
final analysis, including interactive dashboards and causal
inference.
1-6
Data & Bias Discovery
7-13
Modeling & Fairness
15-23
Advanced Analysis
24-30
Synthesis & Outputs
Tech Stack
🐍 Python 3.12+
🔬 scikit-learn
⚖️ Fairlearn
🔥 PyTorch
🤖 BERT
🕸️ NetworkX
🐼 Pandas
📊 Statsmodels
📈 Matplotlib/Seaborn